
En este post haremos un recorrido primero explicando qué son estos dos componentes InfluxDB y Grafana, que suelen irde la mano y tan usados en instalaciones de Home Assistant.
No nos quedaremos solo en una mera explicación, pues veremos las ventajas reales de usarlos en conjunto, y por supuesto iremos paso a paso en su instalación, configuración y uso final.
Decir que podemos usar directamente Grafana con cualquier base de datos (Mysql, MariaDB, etc) pero las consultas serán complejas al tener que tener en cuenta la estructura interna de la basede datos.
Tabla de contenidos
- ▶️ Ventajas de usar InfluxDB en Home Assistant
- ▶️ ¿Puedo usar InfluxDB como BBDD principal en Home Assistant?
- ▶️ ¿Porqúe usar Grafana?
- ▶️ Instalación de InfluxDB en Home Assistant
- ▶️ Configuración del acceso a InfluxDB
- ▶️ Creación de una base de datos en InfluxDB
- ▶️ Configuración de InfluxDB en Home Assistant
- ▶️ Guardando datos a largo plazo
- ▶️ Creación de Continuous Query (o consulta periódica)
- ▶️ Instalando Grafana en Home Assistant
- ▶️ Graficando datos con Grafana
▶️ Ventajas de usar InfluxDB en Home Assistant
InfluxDB está adaptado específicamente para series temporales, es decir, es el instrumento ideal para representar la evolución en el tiempo de cualquier dato (una temperatura, o el consumo eléctrico).
Nosotros somos grandes defensores del protocolo Zigbee frente a WiFi, por lo que te recomendamos que empieces con los siguientes componentes que hemos seleccionado:





En el mundo industrial existen sistemas de almacenamiento y gestión de datos históricos muy sofisticados (PI System de Osisoft o Matrikon por citar a dos de los grandes). InfluxDB viene a cubrir el hueco para pequeñas (o no tan pequeñas) empresas y para particulares como nosotros. Al ser Open Source no tendremos que pagar licencias, y el rendimiento es impresionante.
Es perfectamente posible usar cualquier base de datos (a partir de noviembre de 2022, las únicas soportadas por recorder serán SQLite, MariaDB, MySQL y PostgreSQL) para guardar nuestros datos generados con Home Assistant, pero a la hora de acceder a ellos InfluxDB los expone de una manera más intuitiva, sin necesidad de conocer la estructura interna de las tablas que forman esas bases de datos.
Además la ejecución de InfluxDB está muy optimizada y apenas comerá CPU. Ideal por tanto para usar en una Raspberry Pi.
Por último nos permitirá usar otros clientes compatibles, como por ejemplo Grafana.
▶️ ¿Puedo usar InfluxDB como BBDD principal en Home Assistant?
Esta es una duda que puede surgir, y que suele crear confusión, así que mejor aclararlo desde un principio:
La base de datos que usa Home Assistant por defecto es Sqlite, que es perfecta para un uso moderado y un tiempo de almacenamiento corto-medio. Todo dependerá de la cantidad de sensores que tenga vuestro sistema y si tenéis o no configurado la exclusión de alguno de ellos. En este post, por si os interesa, explico un poco más cómo funciona Sqlite y la forma de optimizarlo.
Si por el contrario queréis almacenar más tiempo y/o más sensores, una de las opciones más usadas y recomendables es MariaDB (una variante de MySQL), con la que fácilmente se pueden manejar años de datos y no es muy complicada su instalación.
Bien, todo lo anterior no nos soluciona el problema de tener una base de datos optimizada para series temporales. Y es ahí donde usaremos InfluxDB, y sobre todo por su capacidad de disponer de datos agregados.
Datos agregados son aquellos que construimos usando varios valores (por ejemplo una media horaria. o el valor máximo en 15 minutos). Como os podéis imaginar siempre ocupará menos un dato agregado que todos los valores en bruto. En la terminología de InfluxDB se denomina down-sampled, pero no es más que evitar almacenar todos y cada uno de los valores conservando el significado de lo que se está midiendo.
Por ejemplo, no tiene ningún sentido almacenar una temperatura ambiente cada 5 segundos, pues no cambiará de forma significativa. En ese caso es mejor almacenar una media cada 15 minutos por ejemplo, almacenando 4 valores en vez de 720 cada hora. Veremos cómo hacer esto en este mismo post.
En definitiva, InfluxDB no sustituye a la base de datos de Home Assistant sea cual sea.
InfluxDB será la base de datos que consultará a la principal, y que guardará series temporales agregadas de manera eficiente y a largo plazo (como veremos podremos definir la frecuencia de las consultas, así como cuánto tiempo queremos conservar los datos), mientras que nuestra base de datos principal (SQlite, MySQL, MariaDB o la que se quiera) seguirá recolectando datos en el corto plazo.
▶️ ¿Porqúe usar Grafana?
Casi siempre se da este binomio, y no es por casualidad. Grafana se ha convertido en la solución genérica para representación y monitorización de datos en tiempo real. Lo encontraréis incluso en muchos sistemas de monitoreo de calidad del aire en la Administración, o en la gestión del consumo en comunidades.
Si bien es verdad que InfluxDB viene con su propio sistema para construir interfaces gráficas (dashboards), aquí es donde Grafana gana con diferencia. Su sistema de representación gráfica está más extendido y es más fácil de usar. Para muestra un ejemplo de su propia página:

Grafana podrá incluso integrar distintas fuentes de datos, no solo representando valores desde InfluxDB.
Una vez explicadas algunas ventajas de usar en conjunto InfluxDB y Grafana, vamos manos a la obra instalando todo en nuestro sistema.
▶️ Instalación de InfluxDB en Home Assistant
El siguiente paso es instalar el software que hará de conexión entre nuestro sistema Home Assistant e InfluxDB. Es muy fácil la instalación de este InfluxDB Add-on.
Antes de seguir una advertencia: Ten en cuenta que en este paso y los siguientes vamos a usar nombres de usuario, claves y otros nombres elegidos que no necesariamente deben ser esos, pero para que todo sea claro hemos preferido usar datos concretos. Evidentemente podéis usar los de vuestra elección sin problema.
Desde el menú Supervisor accederemos al Add-on Store, y buscaremos InfluxdB para instalarlo. Desde la versión 2021.12 de Home Assistant se accede desde el menú Configuration > Add-ons, Backups & Supervisor):
Le pondremos por defecto que arranque al inicio, que reporte si alguna vez deja de arrancar, y lo más útil: que nos ponga un enlace directo en la barra lateral:

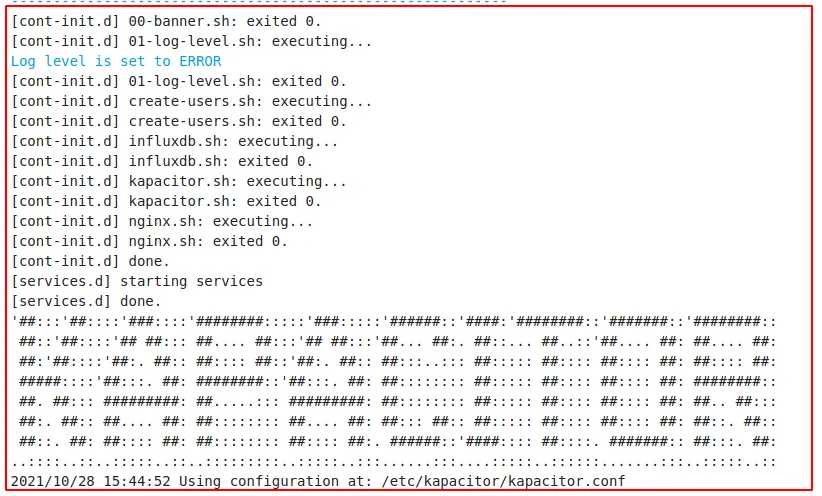
En la pestaña de configuración no hemos modificado casi nada, pero hemos incluido log_level: error para que nos reporte los errores encontrados:
auth: true
reporting: true
ssl: true
certfile: fullchain.pem
keyfile: privkey.pem
envvars: []
log_level: errorEn el proceso de arranque siempre es conveniente echar un vistazo a la pestaña Log. Os debe quedar algo parecido a esto al final:
Una vez arrancado el Add-on, podremos ver el acceso al interface web de InfluxDB en nuestro menú lateral de Home Assistant:
▶️ Configuración del acceso a InfluxDB
Siguiendo las buenas prácticas y el sentido común, vamos a crear un usuario específico para InfluxDB con todos los permisos (ALL). En nuestro caso lo llamaremos influxdb_user y estableceremos una clave (influxdb_user_password). Todo en la sección InfluxDB > influxDB Admin > Users .
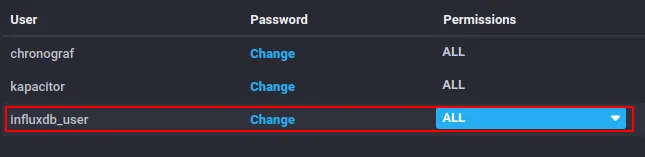
El resto de usuarios (chronograf y kapacitor) los pone el sistema por defecto y no hace falta modificarlos.
▶️ Creación de una base de datos en InfluxDB
Vamos a crear una base de datos específica en influxDB que guardará todo lo relacionado con Home Assistant. La vamos a llamar en nuestro caso HA_db. Para crearla navegaremos a InfluxDB > influxDB Admin > Databases > Create Database:
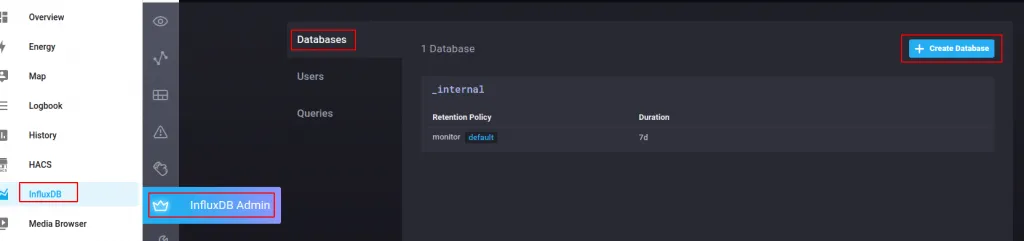
En InfluxDB también hemos de definir cuánto tiempo queremos guardar los datos. Se realiza mediante las políticas de retención de datos.
A la nueva base de datos recién creada se le asocia por defecto una política de retención (sin límite de tiempo) llamada autogen.
Vamos a modificarla eligiendo un período relativamente corto de tiempo. Por ejemplo 7 días (7d) :
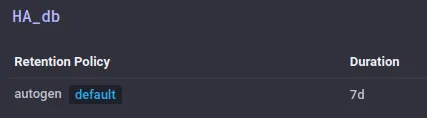
En este apartado Databases también hay otras entradas internas ( _internal ) que dejaremos sin modificar.
Bien, hasta ahora ya tenemos un usuario creado en el entorno InfluxDB, una base de datos y una política de retención de datos por defecto asociada. Más adelante crearemos otra política de retención para el largo plazo.
Lo que nos queda es decirle a Home Assistant cómo tenemos configurado todo esto.
▶️ Configuración de InfluxDB en Home Assistant
Tendremos que modificar el fichero configuration.yaml . Si estás leyendo este post doy por supuesto que sabes dónde se encuentra y cómo modificarlo.
Tendremos que incluir una nueva sección con el siguiente texto con algunos sensores de ejemplo (como siempre cuidado con los espacios):
influxdb:
host: localhost
port: 8086
database: HA_db
username: influxdb_user
password: influxdb_user_password
max_retries: 3
default_measurement: state
include:
entities:
- sensor.ble_temperature_a
- sensor.ble_temperature_b
- sensor.ble_temperature_c
- sensor.ble_temperature_d
La forma en la que InfluxDB clasifica los datos es en función de la unidad de medida (measurement) que se use en Home Assistant (%, ºC, €, etc). Si el sensor no tiene unidad de medida, el sistema usará lo definido en default_measurement, y por tanto va a suponer que se trata de un estado binario (una detección de movimiento, o un sensor de apertura de puerta por ejemplo).
Por eso es importante que en nuestro sistema Home Assistant nos aseguremos que las unidades están definidas correctamente. Normalmente estarán bien, pero si por ejemplo tenemos creado un sensor template, debemos asegurarnos de añadirla unidad de medida correcta en el atributo unit_of_measurement.
Como podéis ver, hemos incluido 4 medidas de temperatura, y tendremos que resetear nuestro sistema para que pueda leer de nuevo esta configuración, o bien en las ultimas versiones, desde el menu Ajustes>Sistema y seleccionando el icono de apagar/encender:

Tras ese reinicio necesario vamos a comprobar que los datos están llegando a la base de datos de InfluxDB.
Para ello navegamos hasta InfluxDB > Explore y formamos una consulta SQL navegando por la estructura: Pimero elegimos nuestra base de datos que tendrá somo sufijo la política de retención por defecto que pusimos (HA_db.autogen), luego elegimos el Measurement que nos interesa (en este caso solo tenemos por ahora ºC) , y dentro del listado de entidades (entity_id con 4 sensores) seleccionamos las que nos interese, y por último dentro de los muchos atributos que podemos seleccionar, vamos a elegir para la prueba el value:

Al ir seleccionando cada opción, el explorador de datos nos ha ido formando una query que será la que nos muestre en forma gráfica, confirmando así que los datos se están empezando a guardar:

Si queréis poner las 4 temperaturas en la misma gráfica debemos agrupar por entity_id:

Posibilidades hay muchas. Por ejemplo podemos cambiar la visualización a tipo Gauge:

Pero no nos vamos a entretener más con esta parte gráfica de InfluxDB porque nos interesa explorar las posibilidades más potentes de Grafana.
▶️ Guardando datos a largo plazo
Vamos a realizar ahora el down-sampling, que como comentamos no es ni más ni menos que resumir varios datos en bruto en uno solo, usando la agregación. Existen varias funciones de agregación (por ejemplo la media o la mediana). Yo personalmente prefiero la mediana como medida representativa pues es más robusta que la media (ver una explicación en esta otra entrada sobre estadística).
Al igual que pusimos la política de retención por defecto (llamada autogen) en 7 días, vamos a crear ahora otra política de retención para guardar 2 años (720d). Lo llamaremos twoyears porque en español quedaría un poco raro dosanos… Desde la sección de InfluxDB Admin > Databases, en el bloque correspondiente a nuestra base de datos HA_bd selecionamos «Add retention policy» y le damos nombre y duración:

▶️ Creación de Continuous Query (o consulta periódica)
Lo que se denomina «Continuous Query» no es ni más ni menos que una consulta SQL que se ejecutará automáticamente cada cierto tiempo.
¿Que para qué queremos una consulta automática?
Porque será la encargada de recopilar de forma períodica cierto número de datos y calcular por ejemplo la mediana de todos ellos. Esta es por tanto la parte clave que nos ayudará a reducir el número de datos y por tanto a almacenar mucho más tiempo.
Para crear la Continuous Query tendremos que teclear directamente nosotros la consulta. Para ello simplemente volveremos a una parte del interface de InfluxDB que ya hemos visitado antes: InfluxDB > Explorer. Desde aquí borraremos cualquier query que pueda aparecer por defecto y crearemos una nueva con el siguiente código:
CREATE CONTINUOUS QUERY cq_celsius_15m ON "HA_db"
BEGIN
SELECT median(value) AS value
INTO HA_db.twoyears."°C"
FROM HA_db.autogen."°C"
GROUP BY time(15m), entity_id
FILL(previous)
END
Advertencia: Como ya dijimos, InfluxDB clasifica las medidas en función de sus unidades. Si se están añadiendo temperaturas, mejor copiad desde Home Assistant en vez de teclearlo, para no usar el carácter «º» del teclado, pues es muy parecido al usado por Home Assistant «°»
Le hemos dado un nombre representativo de la unidad de medida y la frecuencia de ejecución (cq_celsius_15m), tomando los datos desde la política de retención por defecto (la de los 7 días llamada autogen), calculando la mediana (median) y volcando el resultado en la política de retención creada para el largo plazo (twoyears). FILL (previous) indicará que en ausencia de datos tome el último valor conocido y no genere un hueco. Lo haremos para cada entidad de Home Assistant y para cada tramo de 15 minutos (en cláusula GROUP BY)
Lo vemos en este pantallazo para que quede claro dónde ejecutarlo:

Al ejecutarlo (submit query) nos debe responder «Sucess!!«
Para asegurarnos de que está creada vamos a correr esta otra consulta que nos debe devolver precisamente la «Continuous Query» que acabamos de crear:
show continuous queriesSi os habéis equivocado o queréis variar algo no pasa nada. Podemos borrarla con este comando:
DROP CONTINUOUS QUERY "cq_celsius_15m" ON HA_db Otra forma de ver si se está ejecutando es consultar la base de datos interna (_internal.monitor), seleccionando la medida cq (continuous queries), las ejecutadas correctamente (queryOk), y verificamos que el número se va incrementando cada 15 minutos.
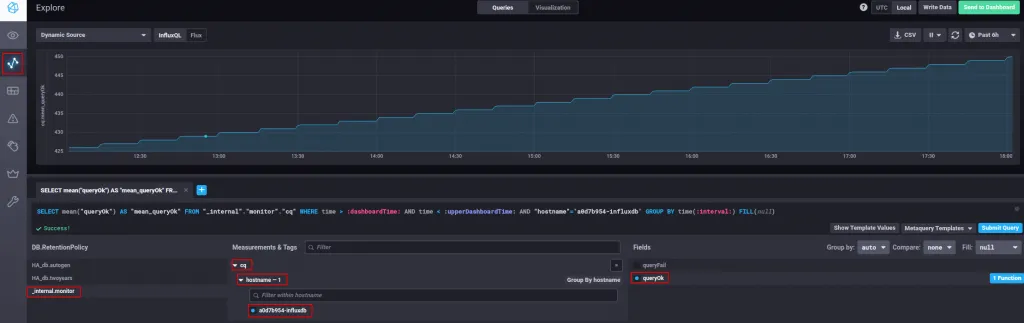
Tendremos que esperar un poco (recordad que esta consulta se ejecuta cada 15 minutos) para empezar a tener datos guardados con la nueva política de retención twoyears.
▶️ Instalando Grafana en Home Assistant
Una vez que tengamos ya datos en InfluxDB tanto a corto como a largo plazo, vamos a la parte de visualización. Para ello vamos a instalar Grafana, navegando de nuevo desde el menú Supervisor > Add-on Store :
Igual que en el caso de InfluxDB, activaremos la opción de poner un acceso directo en el menú lateral de Home Assistant para un fácil acceso., y arrancaremos el Add-on
▶️ Graficando datos con Grafana
Vamos directamente a crear un panel fácil, para que os animéis a descubrir todo lo que se puede hacer, que daría para un blog independiente.
Pero primero vamos a indicar la fuente de datos (datasource) que será nuestra base de datos InfluxDB (HA_bd), bien con datos de 7 días (autogen) o bien con datos hasta 2 años (twoyears). Navegamos hasta Configuration->Data Sources->Data Sources.
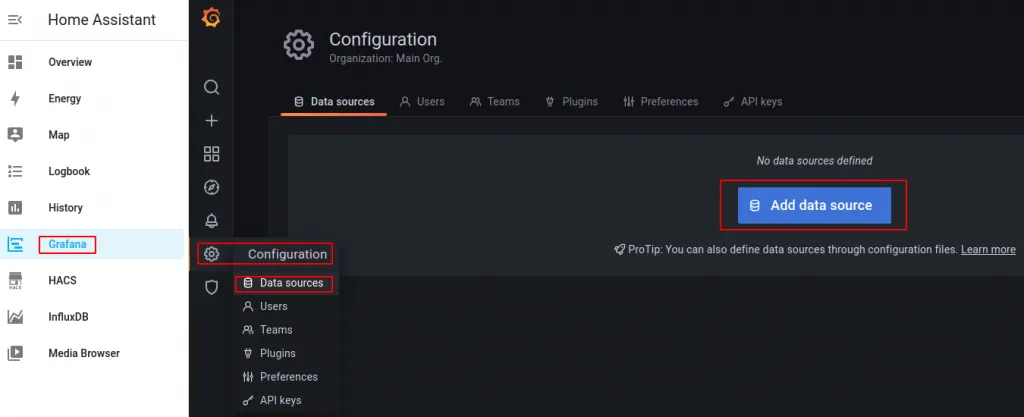
Os saldrán múltiples opciones de bases de datos a las que conectar. Nosotros obviamente elegiremos InfluxDB; para que nos muestre otra pantalla donde tendremos que configurar algunos parámetros.
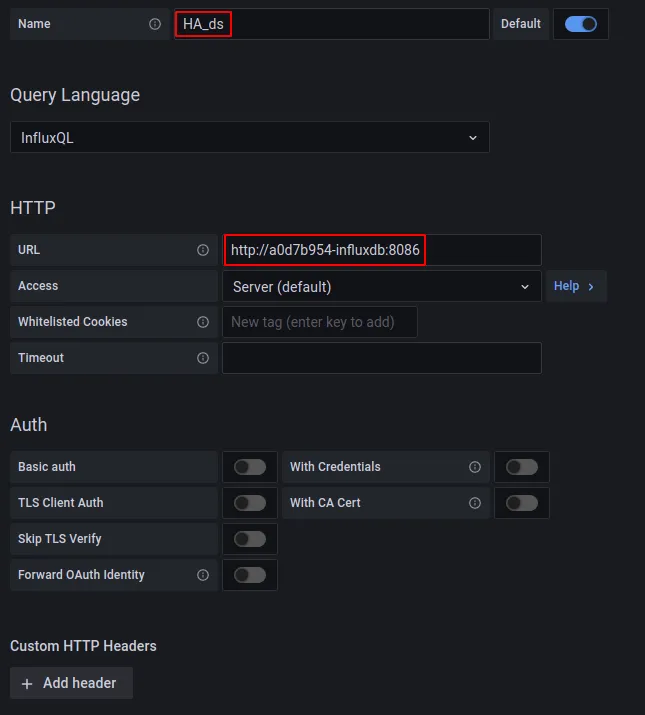
Elegimos el nombre que queramos para identificar esta fuente de datos (nosotros hemos elegido HA_ds ), En URL teclearemos https://a0d7b954-influxdb:8086 ( este es el nombre interno del contenedor del Addon dentro de Home Assistant )
En el apartado InfluxDB Details pondremos el nombre de nuestra base de datos (HA_db), nuestro usuario para InfluxDB (influxdb_user) y su clave correspondiente (influxdb_user_password).
Con esto ya tendremos configurada nuestra fuente de datos. El resto de opciones las podemos dejar tal como están. Si damos a «Save & Test» nos debe contestar «Data source is working«
De nuevo pantallazos para que comprobéis que todo está ok:

Ya tenemos nuestra fuente de datos para poder representar. ¿Cómo lo hacemos? Pues como comentábamos al comienzo de este apartado, creando un panel desde cero, desde Grafana > Create > Dashboard > Add an empty panel y elegiremos la opción «add an empty panel«:
Nos mostrará un panel vacío y en la parte inferior una especie de formulario para formar la consulta que queremos que represente. Por ejemplo, en nuestro caso podemos representar Temperatura_C con la política de retención autogen (recuerda que la definimos con hasta 7 días de datos históricos y por tanto con más resolución). A medida que pulsemos en los campos nos aparecerán las distintas opciones, por lo que no tendremos que teclear nada:
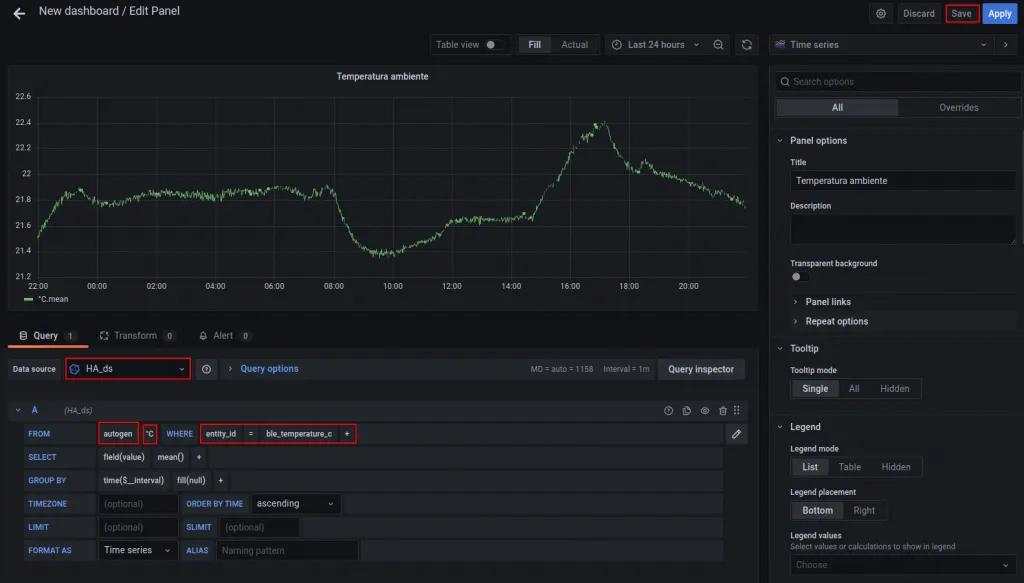
Como podéis apreciar, la cantidad de opciones que hay es abrumadora. Literalmente se puede modificar de todo, desde el título hasta cómo se conectan los distintos valores representados.
Lo mejor es empezar a jugar un poco con cada opción. Es la manera más fácil de familiarizarse.
Cuando salvemos este panel, nos preguntará por el nombre que queramos darle, e incluso podremos organizarlos por carpetas. Por ahora para no complicar dejamos la carpeta General que sale por defecto:
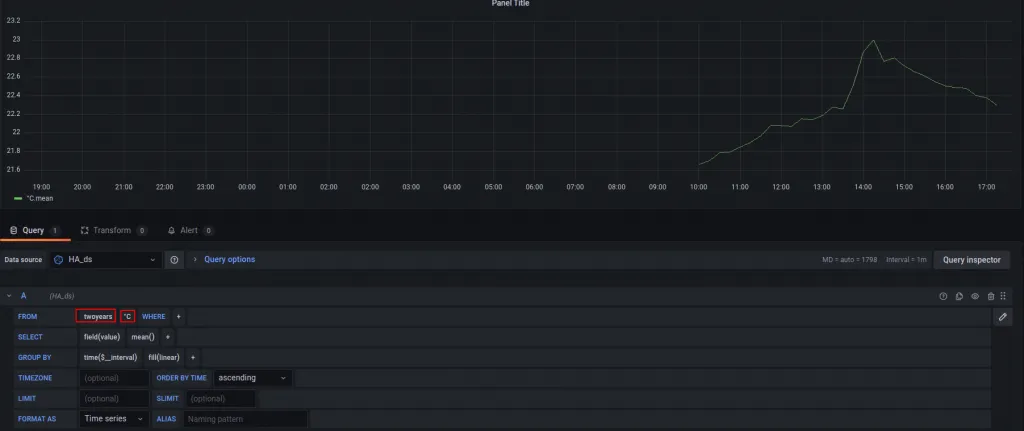
Igualmente podremos graficar datos más antiguos. La única diferencia es que ahora tendremos que seleccionar «twoyears» como política de retención de datos, y la resolución será cada 15 minutos (más que suficiente para una temperatura):
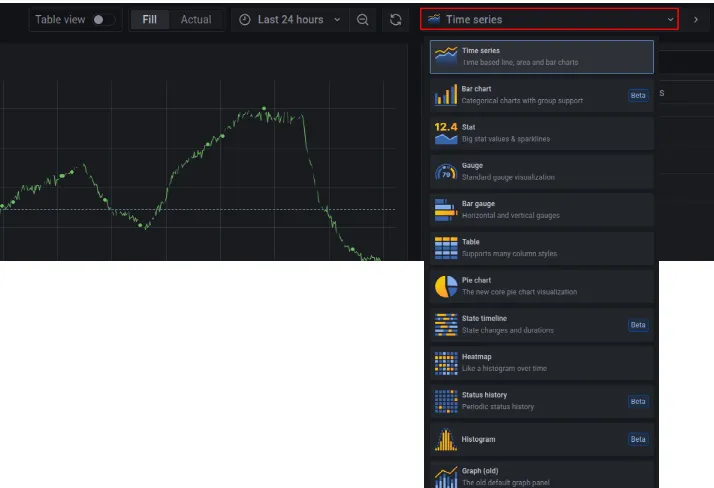
Las distintas opciones gráficas salen en un desplegable donde pone «Time series» en la esquina superior derecha:
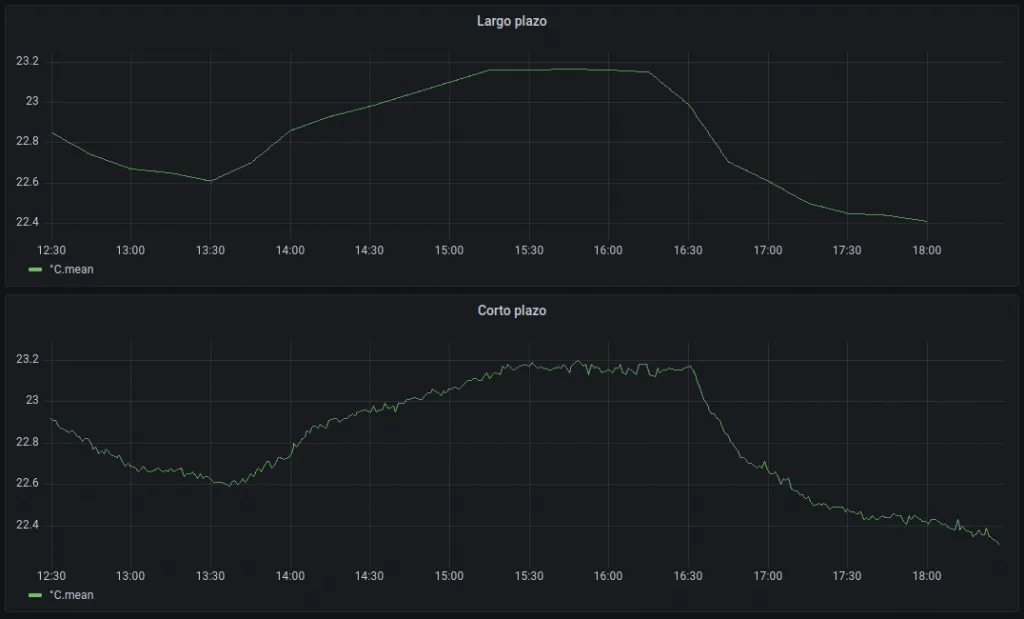
La variabilidad en una medida es un tema interesante, pues parte de esa variación es debida al cambio de la variable (la señal de temperatura en este caso), y otra parte debida a imprecisiones en la medida (ruido). Al representar el largo plazo junto al corto plazo, vemos la simplificación de datos obtenida sin prácticamente pérdida de información:
Como siempre, os animo a investigar y probar todas las opciones que os aparecen en el margen derecho al configurar un panel.
Esta entrada es una introducción, para que se pueda configurar y usar en nuestro sistema Home Assistant. Las posibilidades a partir de aquí son muchísimas, acceso directo de otras personas a vuestros paneles, mezclar diferentes fuentes de datos, transformar con funciones, etc…
Os dejo otras entradas interesantes tanto si estás empezando como si eres ya un usuario avanzado:
- Los juegos que potencian la filosofía STEM (Ciencia, Tecnología, Ingeniería y Matemáticas) tienen beneficios a medio y largo plazo. Invierte en conocimiento y nunca te arrepentirás.

- Como dejar tu casa conectada y segura con las cerraduras inteligentes

- En cualquier proyecto de bricolaje las herramientas correctas son esenciales. Vamos a deciros nuestras favoritas.

- Temperatura y humedad. Mijia con Home Assistant

- Automatiza tu hogar con macros en Home Assistant: simplifica y reutiliza tus mejores templates.

Excelente post, aclara muchos puntos para los que estamos iniciando al igual que otros artículos del blog, me gustaría dejar dos consultas, la primera con la versión core de HA, tienes alguna experiencia?, por más que lo he intentado no logro conectar influx y HA, se me ha hecho todo un poco más complejo al.no tener los addon. Y la otra pregunta un poco fuera del tema, has usado google actions para conectar a un google home o conoces alguna forma de integrar las acciones de voz a este último, saludos u gracias por la info
Gracias por el comentario.
Desgraciadamente nuestro setup de pruebas es supervised, y todavía no hemos encontrado una razón de peso para no dedicar un equipo en exclusiva para Home Assistant con todos sus Addons, aunque docker tiene otras ventajas evidentemente.
Por otro lado, tenemos pensado preparar un post especial de Google Home al igual que hicimos con Alexa
Gracias por la guía! Hacía tiempo que quería instalar Influxdb y Grafana.
Tengo una duda, me he quedado atascado, no entiendo el paso de» Creación de Continuos Query» qué significa cada paso, pues yo no he integrado los mismos sensores que tú, ninguno de temperatura, y me dice que el mensaje en sintaxis es correcto pero que no obtiene respuesta. Entonces necesitaría saber con algo más de detalle que significa ese código y poder adaptarlo a mi caso
Hola Javier, si has llamado igual a tu base de datos (HA_db) y a la política de retención (twoyears), en teoría os tiene que funcionar cambiando a las unicades que uses. La explicación de cada parámetro usado está un par de párrafos abajo del código, y la mejor comprobación que puedes hacer es verificar que se ha creado la query y ver si se va ejecutando tal como se explica, dejando tiempo para que empiece a recolectar algunos datos.
Hola! Tengo el mismo problema. He añadido dos sensores de temperatura y me dice que la sintaxis es correcta pero que no hay datos. Si pruebo la query «twoyears» de la misma manera que comprobamos al principio «db autogen», se me muestra un punto en la grafica (entendiendo que si consulto mas tarde mostrara mas datos y que esta correcta). Debo esperar y poder ejecutar la query:
CREATE CONTINUOUS QUERY cq_celsius_15m ON «HA_db»
BEGIN
SELECT median(value) AS value
INTO HA_db.twoyears.»°C»
FROM HA_db.autogen.»°C»
GROUP BY time(15m), entity_id
FILL(previous)
END
o es que estoy haciendo algo mal? Gracias
Hola Juan. Efectivamente debes esperar un tiempo hasta que la query se ejecute varias veces. De todas formas verifica que el carácter ° sea exactamente el mismo que usa Home Assistant tal como se explica en el post ( ese detalle me dio varios días de batalla hasta que lo identificamos)
Gracias por compartir todo tu conocimiento! Me ha servido de mucha esta guía porque soy de los que los videos tutoriales no me gustan demasiado y prefiero las guías escritas paso a paso.
Muchas Gracias!
Gracias Javier. Comparte el link si es necesario y ayuda a otros. Saludos
Hola, Gracias por estas guías y dedicación, es realmente una ayuda.
Sobre este tema tengo una preocupación, y es saber como realizar un backup o copia de seguridad de los datos almacenados en influxdb. Si tengo HA. OS cuando hago una copia de seguridad completa ¿se copian los datos de influxdb? y si no , como los hago, que para mi es lo mas importante.
Muchas Gracias de nuevo.
Hola Roberto. Estupendo que te guste nuestro artículo. InfluxDB no sustituye a la base de datos de Home Assistant. Solo generará datos agregados para su almacenamiento de manera más eficiente. Si de verdad estás interesado en guardar gran cantidad de datos o durante mucho tiempo, lo ideal es instalar MariaDB, a ser posible en un equipo independiente. En ese mismo artículo se explica cómo realizar copias de seguridad.
Gracias por esta respuesta tan rápida. Actualmente tengo en un PC I5 8G RAM y 250 SSD con HA. OS y con MariaDB instalado como BD de HA, me gustaría usar esa BD para guardar los datos de mi sensores, pero la puesta en marcha me resulta complicado para mis conocimientos, influxdb es mas simple, tal como comentas al inicio del articulo. Con MariaDB y phpMyAdmin todo se ve mas al detalle y puedo importar y exportar datos, cosa que con influxdb es mas cerrado pero mas fácil de poner en marcha. Estaré pendiente de nuevos artículos que seguro me aportaran ideas a poner en marcha.
Hola! Espectacular tener Influxdb y Grafana en HA.
Sería posible añadir el dashboard en forma de tarjeta, panel o lo que sea a nuestro panel de control?
No he sabido hacerlo.
He intentado creando una API y añadiendo una tarjeta de http con la dirección web (que me da la API) pero lo que recibo es formato texto y no se muy bien cual.
Hola Raul, no lo hemos probado, pero deberia funcionar con una tarjeta tipo iframe, en la propiedad URL se debe poner la URL del panel de Grafana. Puedes probar primero con cualquier otra URL publica para ver que te funciona dicha tarjeta.
Buenas noches,
Sigo todos los pasos al pie de la letra pero no consigo que me salta ningún sensor en la BBDD de influxDB.
Tengo Home Assistant instalado en una máquina virtual en un equipo con Debian. ¿tendría que hacer algún cambio en la configuración del archivo configuration.yaml por este motivo?
Gracias.
Hola, en princiio HA no conoce si esta en una maquina virtual o si esta corre bajo un sistema operativo concreto, por lo que no debe influir. Lo mas probable es algun error en espacios, o sintaxis.
debes incluir los sensores que quieras en una seccion influxdb: y dentro de esta tras «include:» en tu fichero configuration.yaml junto que el resto de informacion (usuario, claves, etc).
Verifica tambien que las unidades de medida estn correctas en HA.
Si se están añadiendo temperaturas, mejor copia desde Home Assistant en vez de teclear la unidad de medida, para no usar el carácter «º» del teclado, pues es muy parecido al usado por Home Assistant «°»
Fantástico artículo. Gracias
Buenas tardes,
He intentado varias veces instalar Influx y Grafana para monitorizar consumo y temperatura de mi aerotermia pero siempre me quedo atascado en los primeros pasos cuando se definen los sensores a monitorizar.
En vez de usar los sensores utilizados en el ejemplo (sensor.ble_temperature_a) he usado los sensores de temperatura que ya tiene definidos la integración de la aerotermia en Home Assistant, pero ahi me quedo. Cuando abro el explorador de Influx y pico en la base de datos HA_db/autogen no me sale ningún Measurement para elegir.
Supongo que debe ser una tontería, pero no doy con ella.
Gracias
Hola. Hemos cambiado el código yaml para que puedas copiarlo/pegarlo directamente por si fuera ese el problema. Le daremos de todas formas un repaso por si hubiera algo que corregir. Ya nos comentas. Saludos.
He visto que habéis cambiado el puerto, aun así, sigo en la misma.
En el YAML he puesto los sensores que tengo de un Shelly EM, de un enchufe inteligente que mide consumo y de mi aerotermia, aun así no muestra nada de nada.
Tengo Home Assistant OS montado en una máquina virtual que corre en Debian, no se si esto influye para algo en la configuración del YAML.
Hola de nuevo. Prueba a mirar en Ajustes>Complementos>InfluxDB en Registro por si hay algunos mensajes de error que te puedan dar pistas.
También verifica que el usuario y password en el fichero yaml es correcto, o a cambiar localhost por la IP exacta de tu máquina (entiendo que le asignaste una IP estática).
Y por último, comprueba que no te has saltado el paso de asignar al usuario específico (influxdb_user en el post) todos los permisos (ALL)
Saludos.
buenas. para los que usamos influxdb 2.x hay bastantes diferencias respecto a este manual. y luego en grafana, o por ser una versión más avanzada o bien porque la fuente de datos viene de influxdb 2.x resulta que a la hora de querer crear un panel, hay que hacerlo con código. No salen los desplegables «fáciles» de la parte inferior. Hasta los sensores me toca añadirlos con código…
Se podría hacer una actualización de este método?