En este post os voy a mostrar varias cosas interesantes.
En primer lugar veremos una integración poco conocida de Home Assistant, llamada Statistics , que como su nombre indica está relacionada con parámetros estadísticos, y que nos va a dar mucho juego para nuestras automatizaciones y nuestras notificaciones.
Aprovecharemos este sensor para enseñaros cómo analizar el código fuente de Home Assistant, incluso detectando errores en la documentación.
Y por supuesto crearemos desde cero un sensor Statistics… con Paciencia
Por último, como no podía ser de otra forma, le sacaremos utilidad a estos datos, calculando algunas probabilidades, y lo usaremos en una notificación de Telegram para que nos avise cuando tenga que hacerlo.
Como véis es un ejemplo completo, con todo lo necesario para que lo apliquéis a otros sensores. Estaré encantado de que aportéis ideas en los comentarios. Os dejo aquí una selección de dispositivos muy adecuados para capturar datos agregados junto con este sensor Statistics:








Vamos a empezar por el principio:
Tabla de contenidos
FUNCIONAMIENTO SENSOR STATISTICS
Siempre es bueno empezar por la documentación, y aquí os pongo un pequeño resumen de lo que indica sobre el sensor Statistics:
El sensor Statiscs, básicamente va guardando una lista de valores de otro sensor del que se alimenta, bien sea binario o de estado (valores numéricos), y realiza ciertos cálculos con el conjunto de datos, aunque en el caso del sensor binario solo ofrecerá el conteo de datos.
Para un sensor que toma valores numéricos, esta integración ofrece los siguientes resultados:
- media (mean)
- stdev (desviación estándard) . Hay un error en este nombre. Realmente es standard_deviation
- variance (varianza)
- total (suma de los valores)
- min_value (menor valor en la lista de datos)
- max_value (mayor valor en la lista de datos)
- min_age (fecha/hora del primer dato, el más antiguo)
- max_age (fecha/hora del último dato, el más reciente)
- change
- average_change
- change_rate
Como véis, han sido muy excuetos en dar información de estos atributos, y puede ser el motivo de que este componente no sea muy comprendido. Vamos a arreglar eso.
ANALIZA EL CÓDIGO FUENTE
Como la documentación deja que desear y queremos saber más, vamos a hacer el ejercicio de leer el código fuente para aclarar algunos aspectos del funcionamiento de este sensor Statistics.
No es raro que encontremos sensores como éste, muy útiles pero con pocos ejemplos para entender exactamente cómo funciona. En ese caso, incluso sin saber programar en python se puede «leer» su funcionamiento y aprender bastante.
El código fuente lo podéis encontrar en GitHub – Home Assistant Core
El fragmento que nos interesa para conocer cómo va actualizando estos cálculos está en el fichero sensor.py dentro de la carpeta core/components/statistics:
Casi al inicio del fichero se establecen los valores por defecto, entre otros para el sufijo a añadir al nombre del sensor, el número máximo de datos a tratar y el número de decimales a usar:
DEFAULT_NAME = "Stats"
DEFAULT_SIZE = 20
DEFAULT_PRECISION = 2Incluso vemos algún error en el nombre del atributo de la desviación estándar. Realmente no la denominada stdev, sino standard_deviation . No es de extrañar que sea poco usado:
ATTR_AVERAGE_CHANGE = "average_change"
ATTR_CHANGE = "change"
ATTR_CHANGE_RATE = "change_rate"
ATTR_COUNT = "count"
ATTR_MAX_AGE = "max_age"
ATTR_MAX_VALUE = "max_value"
ATTR_MEAN = "mean"
ATTR_MEDIAN = "median"
ATTR_MIN_AGE = "min_age"
ATTR_MIN_VALUE = "min_value"
ATTR_SAMPLING_SIZE = "sampling_size"
ATTR_STANDARD_DEVIATION = "standard_deviation"
ATTR_TOTAL = "total"
ATTR_VARIANCE = "variance"Veamos al código que nos interesa un poco más, para ver el funcionamiento real.
En la función async_update vemos cómo se actualizan los atributos:
El atributo count está claro, se refiere el número de datos en la lista y con los que va a realizar el resto de cálculos cuando aplique este valor:
self.count = len(self.states)En el caso de mean (media) y median (mediana), que requieren por lo menos 1 dato, y para la standard_deviation (desviación estándard) y variance (varianza), que requieren al menos 2 datos, así como el total, min y max, también es evidente, usando el paquete statistics que se importó al principio del módulo, con la precisión que queramos en el parámetro precision
self.mean = round(statistics.mean(self.states), self._precision)
self.median = round(statistics.median(self.states), self._precision)
...
self.stdev = round(statistics.stdev(self.states), self._precision)
self.variance = round(statistics.variance(self.states), self._precision)
...
self.total = round(sum(self.states), self._precision)
self.min = round(min(self.states), self._precision)
self.max = round(max(self.states), self._precision)Luego actualiza los parámetros min_age y max_age, escogiendo del conjunto de datos, el más antiguo [0] y el más reciente [-1]. Recordad que en python una lista se accede por sus índices empezando por 0, pero también podemos usar índices negativos para contar desde el final, por eso es tan usual ver [-1] para referirse al último de la lista.
Es decir, min_age será la fecha/hora del primer elemento de la lista, y max_age el del último. Os pongo los fragmentos importantes juntos aunque pertenezcan a distintas funciones:
self.ages.append(new_state.last_updated)
...
self.min_age = self.ages[0]
self.max_age = self.ages[-1]Los parámetros change, average_change y change_rate son un poco más confusos, pues se van calculando en varios pasos:
self.change = self.states[-1] - self.states[0]
self.average_change = self.change
...
self.average_change /= len(self.states) - 1
...
time_diff = (self.max_age - self.min_age).total_seconds()
self.change_rate = self.change / time_diffEs decir, el parámetro change es simplemente el último valor de la lista menos el primero.
average_change es calculado como la media de las diferencias entre un valor y el siguiente de la lista, y change_rate será la tasa de cambio en todo el período comprendido entre el primer elemento y el último, pero medido por segundos, de ahí que casi siempre lo verás en 0 a menos que subas mucho la precisión, o bajes mucho el sampling_size para que los segundos transcurridos no den un número muy grande.
IMPLEMENTANDO EL SENSOR EN HOME ASSISTANT
Una vez que sabemos perfectamente cómo funciona, vamos a crear dicho sensor, que tomará datos de otro sensor ya definido que nos da la temperatura de la CPU (podéis usar cualquier otro que os interese).
Si todavía no tenéis pensado en qué equipo correr Home Assistant y poder usar este tipo de integraciones, os dejo dos buenas ofertas que tras buscar y buscar creo que merecen la pena:




Debemos modificar nuestro fichero configuration.yaml para incluir lo siguiente:
sensor:
- platform: statistics
entity_id: sensor.cpu_temperature
name: cpu.temperature.stats
precision: 4
sampling_size: 60
max_age:
minutes: 60De entre los parámetros de configuración, aparte de poder darle un nombre , podemos definir lo siguiente:
- sampling_size –> Define en número máximo de datos que tomará para realizar los cálculos. Por defecto 20 datos.
- max_age –> Máximo tiempo a partir del cual se irán descartando datos. Si ponemos por ejemplo 60 miuntos, pues tendrá en su lista de datos interna tantos valores como lleguen en 1 hora, siempre y cuando no sobrepasen lo especificado en sampling_size.
- precision –> Precisión que queramos en los cálculos (por defecto 2 decimales)
En este paso de configuración, es muy importante estimar primero el número de valores que pueden llegar en el intervalo max_age especificado.
Os voy a poner un ejemplo: Si quiero analizar una temperatura de CPU que ya tengo (ver cómo tener esta integración de manera fácil), y veo previamente que llegan entre 40 y 50 datos en una hora. En este caso puedo poner sampling_size=60 y max_age=1 hora sin problema, pues en esa hora no llegarán más de 60 datos.
Si se dejara sampling_size=20, va a descartar casi la mitad de los datos que llegan en una hora, y por tanto nos daría medidas erróneas.
Tras resetear Home Assistant (o cargar sólo la opción STATISTICS ENTITIES en el menú Server Controls) , ya tendremos creado nuestro nuevo sensor:
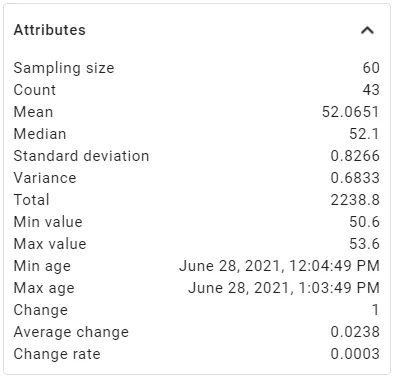
Una vez veamos que funciona correctamente, podríamos excluir de recorder el sensor original si no nos interesa, para ahorrar espacio. Personalmente creo que para señales con mucha variabilidad/ruido, da más información la media que la medida puntual.
Para no guardar nunca más estos valores del sensor original, lo incluiremos dentro del apartado exclude, en la sección recorder de nuestra configuración:
recorder:
exclude:
entities:
- sensor.cpu_temperatureTened en cuenta que si reiniciamos Home Assistant en este caso, al no existir datos históricos, tendremos que esperar un poco hasta tener datos suficientes para que se muestren resultados representativos en nuestro nuevo sensor.
USO DE LOS DATOS
Bien, ya que sabemos cómo calcula los distintos atributos nuestro componente Statistics, y tenemos el sensor creado, vamos a hacer uso de dos de esos parámetros, en concreto la media (mean) y la desviación típica. (standard_deviation)
No vamos a entrar en temas sobre las distintas distribuciones de datos que podemos encontrarnos, pero si sigues leyendo verás algunas aplicaciones de la distribución Normal que te servirán en muchas ocasiones.
Como vamos a suponer que la distribución de los valores sigue una forma acampanada (distribución Normal), al realizar nuestro análisis y si somos serios, debemos comprobar primero que efectivamente se ajusta a dicha distribución.
Y como en anteriores entradas usaremos Google Colab para tener un entorno de trabajo con dichos datos y poder visualizarlos bien.
Antes de empezar, una precaución: Debemos tener cuidado de analizar datos más o menos estables. Por ejemplo, si la temperatura de mi CPU baja de unos 70ºC a unos 55ºC porque he encendido un aire acondicionada en la habitación, y analizo justo en el momento de la transición tendremos lo siguiente:

Como véis salen 2 distribuciones similares pero con la media desplazada. Mejor elegir un período estable.
Los datos vendrán directamente de nuestra base de datos (en mi caso sqlite, que es la opción por defecto en la instalación) durante una hora. También es fácil la modificación y optáis por exportar y obtener ficheros csv de Grafana si lo usáis.
En otro post, por no repetirme, os expliqué cómo acceder a la base de datos (home-assistant_v2.db) y enlazarla con Google Colab. Os dejaré el notebook al final del post.
#Paquetes necesarios
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import sqlite3
# Creamos la conexión con la base de datos de Home Assistant
# Cambiar a vuestro propio path
con=sqlite3.connect('/content/drive/MyDrive/Colab Notebooks/Explore HA DB sqlite/home-assistant_v2.db')
# Lectura de datos a un dataframe usando una consulta SQL contra la base de datos de Home Assistant
# Filtrando para una semana en concreto para sensor.cpu_temperature
temperature_df=pd.read_sql_query('SELECT state FROM states WHERE last_changed BETWEEN "2021-06-03 12:00" AND "2021-06-03 13:00" and entity_id = "sensor.cpu_temperature"',con)
temperature_df=temperature_df.astype(float)
Hasta aquí la lectura de datos desde sqlite hasta nuestro notebook de Google Colab. Veamos ahora la representación de los mismos:
# Nuestro primer gráfico. Histograma de valores
plt.figure(figsize=(16, 6))
g1=sns.histplot(data=temperature_df, x="state", binwidth=0.5, kde=True)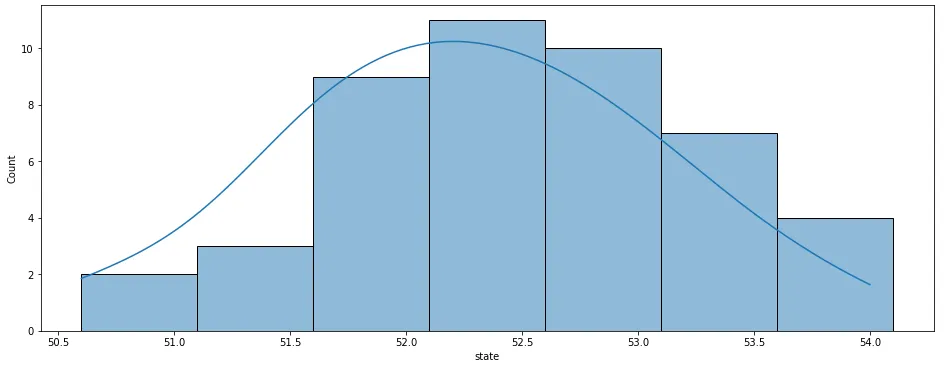
Visualmente ya apreciamos la famosa curva acampanada, pero podemos hacerlo aún mejor con uno de los varios tests disponibles:
# Comprobación formal. Test shapiro-wilk
from scipy.stats import shapiro
stat,p=shapiro(temperature_df)
print (p)Si ejecutáis este código, veremos que nos da un resultado para el p-valor de 0.1612798124551773
En otro post explicaré en detalle todo el tema de contraste de hipótesis, pero creedme por ahora que si el p-valor>0.05, podemos estar seguros al 95% de que nuestros datos siguen una distribución normal (como en este caso)
Veamos, una vez que hemos demostrado con suficiente confianza que los datos siguen esa distribución, algunas conclusiones de ejemplo que podemos calcular:
Por ejemplo, para calcular la probabilidad de que nuestra temperatura sea menor de 54ºC usaremos la función cdf (cumulative distribution function) del paquete scipy con una media y desviación estándar sacada de nuestra muestra de datos:
# Probabilidad de que nuestra temperatura tenga valores inferiores a 54ºC
# mean=52.57 ºC , stdev=0.79 ºC
dist_temp= stats.norm(52.27,0.79)
(dist_temp.cdf(54))*100Para este caso concreto nos da un valor de 98.57% de probabilidad de que nuestro sensor de temperatura tenga valores inferiores a 54 ºC
Todo esto para qué nos vale, os estaréis preguntando a estas alturas.
Pues bien, nosotros acabamos de crear un sensor Statistics, que entre otras cosas nos da en tiempo real la media y la desviación típica de las temperaturas de mi CPU en los últimos 60 minutos. Y las matemáticas me dicen (ver distribución normal) que el 0.15% de los datos (15 de cada 10000 valores) serán mayores que mean+3*stdev
Ergo… le puedo decir a Home Assistant que me avise de una forma más inteligente, cuando el valor sea superior a ese límite variable (mean+3*stdev) como valor extremo.
El template en nuestro fichero de configuración para crear este límite dinámico será el siguiente:
cpu_temperature_limit:
friendly_name: "Límite temperatura CPU"
unit_of_measurement: 'ºC'
value_template: "
{% set mean=states('sensor.cpu_temperature_stats') |float %}
{% set stdev=state_attr('sensor.cpu_temperature_stats', 'standard_deviation') |float %}
{{ mean + 3 * stdev }}"Os dejo en este enlace el notebook Jupyter por si queréis copiarlo y jugar un poco con vuestros propios sensores.
Vamos a ver la automatización para enviar el mensaje a Telegram que nos avise de subidas bruscas de temperatura.
NOTIFICACIÓN EN TELEGRAM
Por no hacer el post muy extenso, os voy a remitir a la explicación paso a paso para mandar notificaciones a Telegram, y solo dejaré aquí la automatización necesaria (en yaml) para mandar un mensaje cuando nuestra temperatura esté por encima de la media horaria calculada + 3 veces su desviación típica, que como ya hemos visto no será muy común. Tened en cuenta que lo interesante es que dicho valor de notificación será variable, y se irá adaptando según los valores de nuestro nuevo sensor Statistics:
alias: Alerta temp. CPU Raspberry
description: ''
trigger:
- platform: template
value_template: '{{ ( sensor.cpu_temperature ) > ( sensor.cpu_temperature_limit ) }}'
condition: []
action:
- service: telegram_bot.send_message
data:
title: Alerta Raspberry Pi
message: |-
Temperatura alta CPU
{{states('sensor.cpu_temperature_stats')}} > {{states('sensor.cpu_temperature_limit')}}
target: -528825799
mode: singleOs dejo un listado con otras entradas interesantes:
- Explicamos de forma sencilla el funcionamiento de las interferencias en WiFi y sus soluciones.
- Aliexpress tiene los componentes más baratos para hacernos con un ejército de dispositivos inteligentes. Nuestra casa domótica a precios asequibles

- Las notificaciones son importantes en un hogar inteligente, pero cuando unimos Home Assistant y Telegram, el resultado supera todo lo esperado. Fiabilidad y flexibilidad

- El desconocido y útil sensor «Statistics» en Home Assistant. Con ejemplos concretos para aprender a usarlo.

- Home Assistant Green: La solución perfecta para convertir tu Hogar Digital en un espacio inteligente. Y lo mejor el precio…
